По почерку узнать человека: Как определить характер по почерку
Видео: как по почерку узнать о психических проблемах
|
Ника ШумерскаяНика Шумерская Райтер редакции сайта Пятого канала Общество Эксклюзив3 966
Эксклюзив
Фото, видео: depositphotos / visochin_o; 5-tv. ru
ru
Почерк — это инструмент мозга, отражение нашего внутреннего «я», нашего характера и даже болезней. Расшифровкой написанного занимаются графологи, один из них — Оксана Поротова в беседе с 5-tv.ru рассказала, какие признаки письма заставят вас задуматься о том, что у человека имеются психологические или психические проблемы.
Принцип проведения графологического анализа основан на гештальт-подходе, то есть почерк человека оценивается как в целом, так и по совокупности ряда графических признаков, они указывают на события в его жизни и связанные с ними чувства. Поэтому сказать однозначно, что перед вами человек с проблемами, практически сложно.
Призовите на помощь свою наблюдательность, советует эксперт, и сначала оцените внешнее состояние человека и его разговоры. Прежде всего, как психические, так и психологические проблемы скрываются в голове: много мыслей и различных эмоций, причем они далеко не всегда положительные.
«Через руку мы транслируем свои эмоции, чувства, установки, темперамент, характер: все это мы выплескиваем на бумагу. В зависимости от качества внутреннего содержания зависит и качество почерка»,
Depositphotos / alphaspirit
Специалист отметила, что о наличии проблем судить можно в зависимости от уровня почерка: при высоком уровне почерка интерпретация будет положительная, более низкий свидетельствует о сниженных психологических характеристиках.
Признаки почерка низкого уровня:- искажения букв;
- сниженная читабельность;
- буквы как мелкие, так и чересчур крупные;
- строки могут быть не ровные;
- они могут быть восходящие, или, напротив, нисходящие.
Эксперт добавила, что большое значение также имеет наполненность пространства листа, что написано на полях. Неровное левое поле может рассказать о беззаботном и неорганизованном характере человека, а также о его некой распущенности. Корявое поле с правой стороны свидетельствует о неумении контролировать свои эмоции и идти на поводу у своих желаний.
Корявое поле с правой стороны свидетельствует о неумении контролировать свои эмоции и идти на поводу у своих желаний.
handwritter.ru
«Лист бумаги — это мир, в котором человек функционирует, а взаимодействует он с людьми как своего, так и внешнего круга», — заключила Оксана Поротова.
В остальном следует обращать внимание на нюансы. Например, зигзагообразные линии присущи неврастеникам или алкоголикам, «дрожащие» буквы — у истеричной личности, украшательства и завитки могут свидетельствовать об отсутствии воли. В любом случае, только по одному признаку однозначные выводы делать не стоит. Смотрите в комплексе, рекомендует эксперт.
Ранее 5-tv.ru рассказывал, как по почерку распознать агрессивного человека.
Психология Психиатрия Болезни
Читайте также
0°
754 мм рт.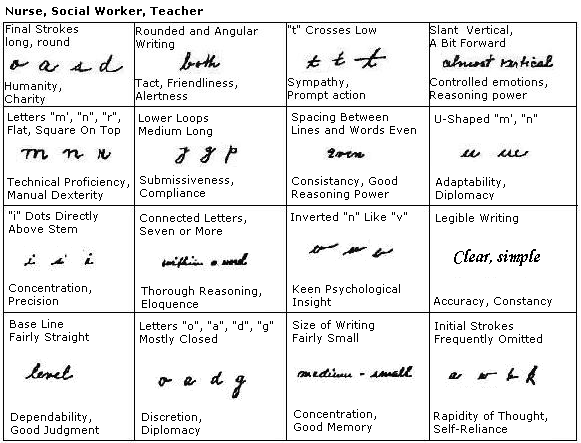
80%
70.12
-0.40
76.22
-0.08
🧙♀ Гороскоп на сегодня, 1 февраля, для всех знаков зодиака
Узнать человека по почерку. Продолжение
https://radiosputnik.ria.ru/20200123/1563767884.html
Узнать человека по почерку. Продолжение
Узнать человека по почерку. Продолжение — Радио Sputnik, 23.01.2020
Узнать человека по почерку. Продолжение
Один из способов исследования личности — анализ почерка. Почерк может колебаться в зависимости от настроения пишущего, также он меняется с годами. Но все это… Радио Sputnik, 23.01.2020
2020-01-23T10:33
2020-01-23T10:33
2020-01-23T10:48
в эфире
подкасты – радио sputnik
проще говоря
/html/head/meta[@name=’og:title’]/@content
/html/head/meta[@name=’og:description’]/@content
https://cdnn21.img.ria.ru/images/156376/78/1563767877_0:3:1036:586_1920x0_80_0_0_9aaac0ebeacd4b29c1496c51b46181f8.
Узнать человека по почерку. Продолжение
Один из способов исследования личности — анализ почерка. Почерк может колебаться в зависимости от настроения пишущего, также он меняется с годами. Но все это только увеличивает достоверность анализа. Сегодня в День почерка, разбираем секреты ручного письма с помощью эксперта. В студии радио Sputnik эксперт-графолог, руководитель центра изучения почерка «Современная Графология» Ирина Бухарева. — — Сегодня ребенка нужно учить писать. Сейчас этому мало уделяется внимания. Почерк ребенка, даже в раннем возрасте обладает индивидуальными характеристиками, и никакие тренировки не в силах это изменить. — Будущее сказать по почерку невозможно. Возраст можно сказать — но он может отличаться от даты в паспорте. Потому что мы видим возраст психологический. Также не всегда возможно с точностью определить пол писавшего. — Пишет не рука, пишет мозг. Если поменялся почерк, значит поменялись вы.
audio/mpeg
Узнать человека по почерку. Продолжение
Продолжение
Один из способов исследования личности — анализ почерка. Почерк может колебаться в зависимости от настроения пишущего, также он меняется с годами. Но все это только увеличивает достоверность анализа. Сегодня в День почерка, разбираем секреты ручного письма с помощью эксперта. В студии радио Sputnik эксперт-графолог, руководитель центра изучения почерка «Современная Графология» Ирина Бухарева. — — Сегодня ребенка нужно учить писать. Сейчас этому мало уделяется внимания. Почерк ребенка, даже в раннем возрасте обладает индивидуальными характеристиками, и никакие тренировки не в силах это изменить. — Будущее сказать по почерку невозможно. Возраст можно сказать — но он может отличаться от даты в паспорте. Потому что мы видим возраст психологический. Также не всегда возможно с точностью определить пол писавшего. — Пишет не рука, пишет мозг. Если поменялся почерк, значит поменялись вы.
audio/mpeg
Один из способов исследования личности — анализ почерка. Почерк может колебаться в зависимости от настроения пишущего, также он меняется с годами. Но все это только увеличивает достоверность анализа. Сегодня в День почерка, разбираем секреты ручного письма с помощью эксперта.В студии радио Sputnik эксперт-графолог, руководитель центра изучения почерка «Современная Графология» Ирина Бухарева.- Сегодня ребенка нужно учить писать. Сейчас этому мало уделяется внимания. Почерк ребенка, даже в раннем возрасте обладает индивидуальными характеристиками, и никакие тренировки не в силах это изменить. — Будущее сказать по почерку невозможно. Возраст можно сказать — но он может отличаться от даты в паспорте. Потому что мы видим возраст психологический. Также не всегда возможно с точностью определить пол писавшего. — Пишет не рука, пишет мозг. Если поменялся почерк, значит поменялись вы.
Но все это только увеличивает достоверность анализа. Сегодня в День почерка, разбираем секреты ручного письма с помощью эксперта.В студии радио Sputnik эксперт-графолог, руководитель центра изучения почерка «Современная Графология» Ирина Бухарева.- Сегодня ребенка нужно учить писать. Сейчас этому мало уделяется внимания. Почерк ребенка, даже в раннем возрасте обладает индивидуальными характеристиками, и никакие тренировки не в силах это изменить. — Будущее сказать по почерку невозможно. Возраст можно сказать — но он может отличаться от даты в паспорте. Потому что мы видим возраст психологический. Также не всегда возможно с точностью определить пол писавшего. — Пишет не рука, пишет мозг. Если поменялся почерк, значит поменялись вы.
Радио Sputnik
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
2020
Радио Sputnik
1
5
4.7
96
internet-group@rian. ru
ru
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Новости
ru-RU
https://radiosputnik.ria.ru/docs/about/copyright.html
https://xn--c1acbl2abdlkab1og.xn--p1ai/
Радио Sputnik
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
1920
1080
true
1920
1440
true
https://cdnn21.img.ria.ru/images/156376/78/1563767877_126:0:910:588_1920x0_80_0_0_d31f90698cefa71e6dc8fc75e0ba53f4.jpg
1920
1920
true
Радио Sputnik
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og.xn--p1ai/awards/
Радио Sputnik
1
5
4.7
96
7 495 645-6601
ФГУП МИА «Россия сегодня»
https://xn--c1acbl2abdlkab1og. xn--p1ai/awards/
xn--p1ai/awards/
в эфире, подкасты – радио sputnik, аудио
В эфире, Подкасты – Радио Sputnik, Проще говоря
Распознавание рукописного ввода: определение, методы и использование
Нужны дополнительные ресурсы? Ознакомьтесь с другими нашими статьями:
- 15+ лучших идей проекта компьютерного зрения для начинающих на 2022 год
- 20+ наборов данных компьютерного зрения с открытым исходным кодом
- Аннотация изображения: определение, варианты использования и типы
- Введение в сегментацию изображения: глубокое обучение по сравнению с традиционным
Что такое распознавание рукописного ввода?
Распознавание рукописного ввода (HWR) — это способность компьютеров и мобильных устройств получать и интерпретировать рукописный ввод. Входы могут быть офлайн (сканированные с бумажных документов, изображений и т.п.) или онлайн (улавливаются от движения ручек на специальном дигитайзере, например).
Система распознавания рукописного ввода также включает в себя форматирование, сегментацию на отдельные символы и обучение языковой модели, которая учится составлять осмысленные слова и предложения.
Наиболее популярным методом распознавания рукописного текста является оптическое распознавание символов (OCR). Это позволяет нам сканировать рукописные документы, а затем преобразовывать их в обычный текст с помощью компьютерного зрения.
Преимущества распознавания рукописного ввода
Многие повседневные варианты использования распознавания рукописного ввода делают его полезным в различных отраслях. Давайте рассмотрим несколько преимуществ внедрения этой технологии.
Улучшенное хранение данных
Распознавание рукописного ввода прокладывает путь к оптимальному хранению данных.
Многие файлы, контракты и личные записи содержат рукописную информацию, такую как оригинальные подписи или заметки, которые можно преобразовать в электронный текст с помощью технологий распознавания рукописного текста.
Для электронных данных требуется меньше физического пространства и ресурсов, чем для хранения физических файлов. Это экономично и избавляет от необходимости сортировать, упорядочивать и искать информацию в бумажных документах вручную.
Несколько отраслей уже начали внедрять эту технологию:
- Страховой и банковский секторы оцифровывают формы, налоговые квитанции и историю транзакций в виде электронных PDF-файлов и проверку подписи
- В розничной торговле хранятся счета и история транзакций клиентов
- Медицинские учреждения внедряют стратегии работы с цифровыми данными, такие как электронные медицинские карты (EHR), чтобы уменьшить количество ошибок, вызванных неразборчивыми шрифтами.
- Логистические компании используют технологии HWR для сканирования коносаментов и обнаружения меток на посылках для их сортировки.

Более быстрый поиск информации
Благодаря распознаванию рукописного ввода и электронному хранению данных мы можем извлекать данные намного быстрее, чем из физических копий.
Мы можем быстро найти сохраненную электронную информацию, используя поиск файлов и указав, что мы ищем.
Это похоже на то, что ИТ-индустрия делает для поисковой оптимизации. Индексация интернет-ресурсов упростила поиск информации по ключевым словам в море контента.
Улучшенная доступность
Способность распознавания рукописного ввода идентифицировать текст из изображений и видео и сохранять его в текстовой форме также может способствовать повышению доступности.
Технология оптического распознавания символов используется для преобразования текста в речь, что помогает слепым и слабовидящим людям. Envision представила умные очки на базе искусственного интеллекта с возможностью оптического распознавания символов для чтения любого текста из любого источника.
В сфере образовательных технологий OCR может помочь делать заметки или преобразовывать математические уравнения, что значительно облегчает учебу. Например, Microsoft Math позволяет сделать снимок рукописной математической задачи, а система предоставит объяснения, примеры, решения, соответствующие учебные материалы и т. д.
Например, Microsoft Math позволяет сделать снимок рукописной математической задачи, а система предоставит объяснения, примеры, решения, соответствующие учебные материалы и т. д.
Улучшение обслуживания клиентов
Распознавание рукописного ввода может помочь улучшить бизнес-процессы и сделать их работу более удобной и безопасной для своих клиентов.
Различные организации могут легко оцифровывать рукописные формы, предоставленные их клиентами, для облегчения доступа и более экономичного хранения. Более того, банки, медицинские учреждения и страховые компании, работающие с персональными данными, могут надежно хранить документы в облачных хранилищах. Отсканированные данные требуют надлежащей аутентификации для доступа, что снижает риск нарушения безопасности по сравнению с хранением печатных копий.
Проблемы распознавания рукописного ввода
Как и любая новая технология, распознавание рукописного ввода сопряжено со своими проблемами. Рассмотрим несколько наиболее актуальных.
Различные языковые модели
Из-за большого количества рукописей, вызванного разнообразием языков и алфавитов, которые различаются от региона к региону, область распознавания рукописного текста ограничена и требует полного просмотра преобразованного текста для сохранения оригинальной рукописи. в электронном формате.
Большое разнообразие
Почерк меняется от человека к человеку. Штрихи, неровности, интервалы между буквами и символами, а также блочный или курсивный почерк затрудняют достижение точности технологиями распознавания рукописного ввода.
Плохое качество изображения
Качество и точность преобразованного текста зависят от качества изображения и присутствующего шума, что затрудняет обработку старых документов, которые со временем ухудшаются.
💡 Профессиональный совет: Ищете текстовый сканер, облегчающий идентификацию документов? Ознакомьтесь с инструментом обработки документов V7.Методы распознавания рукописного ввода
Онлайновая и офлайновая системы распознавания рукописного ввода [источник] Существует два типа распознавания рукописного ввода в зависимости от того, когда происходит идентификация.
Распознавание рукописного ввода в режиме онлайн
Распознавание рукописного ввода в режиме онлайн включает в себя автоматическое преобразование текста по мере его написания на уникальном дигитайзере или цифровой панели с датчиком, который улавливает движения кончика пера и использует эти динамические данные для оценки символов и слов по мере их появления. пишутся.
Основными функциями, которые позволяют онлайн-системе распознавания рукописного ввода предсказывать текст, являются:
a) качество линии
b) скорость письма/слова
c) исполнение букв автоматическое преобразование изображения текста в буквенные коды, используемые в компьютерах и приложениях для обработки текста. Данные, полученные в таком виде, представляют собой статический снимок почерка.
Без информации о нажиме пера, направлении штриха и т. д. добиться точности при автономном распознавании сложнее. Однако она по-прежнему востребована, особенно с учетом необходимости оцифровки существующих исторических и архивных документов.
Методы распознавания рукописного текста и вспомогательные архитектуры
Существует несколько методов распознавания человеческого почерка с помощью машинного обучения, и обязательно появятся новые технологии.
Здесь мы суммируем наиболее известные подходы и алгоритмы распознавания рукописного ввода.
CapsNets
Капсульные сети — это одна из новейших и наиболее совершенных архитектур нейронных сетей, которая рассматривается как усовершенствование существующих технологий машинного обучения.
Слой пула в сверточном блоке используется для уменьшения размерности данных и достижения пространственной инвариантности, что означает, что он идентифицирует и классифицирует объект независимо от того, где он находится на изображении.
Одним из основных недостатков является то, что при объединении теряется много пространственной информации о вращении объекта, местоположении, масштабе и других позиционных атрибутах.
Другим недостатком является то, что если положение объекта слегка изменено, активация не меняется вместе с его пропорциями. Это приводит к хорошей точности классификации изображений, но низкой производительности, если вы хотите найти объект именно там, где он находится на изображении.
Это приводит к хорошей точности классификации изображений, но низкой производительности, если вы хотите найти объект именно там, где он находится на изображении.
Капсула — это блок нейронов, в котором хранится различный набор информации (о его положении, вращении, масштабе и т. д.) об объекте, который он пытается идентифицировать на заданном изображении в высоком разрешении. -мерное векторное пространство, где каждое измерение представляет что-то особенное в объекте.
Ядра, которые генерируют карты объектов и извлекают визуальные объекты, работают с динамической маршрутизацией, объединяя индивидуальные мнения нескольких групп, называемых капсулами. Это приводит к эквивалентности между ядрами и повышает производительность по сравнению с CNN.
На изображении выше показано, как работает сеть CapsNet, когда входные данные изменяются и сжимаются после прохождения через два сверточных блока для формирования 32 первичных капсул по 6 x 6 x 8 капсул в каждой. Эти первичные капсулы подаются в капсулы более высокого уровня, всего десять капсул с 16 размерами каждая, и для этих капсул более высокого уровня рассчитывается предельная потеря для определения вероятности класса.
Эти первичные капсулы подаются в капсулы более высокого уровня, всего десять капсул с 16 размерами каждая, и для этих капсул более высокого уровня рассчитывается предельная потеря для определения вероятности класса.
CNN будут лучше распознавать рукописный текст, если обучающие данные значительны, поскольку модели необходимо изучить большое количество вариаций, чтобы приспособиться к различным стилям почерка. CapsNets помогает уменьшить объем необходимых данных, сохраняя при этом высокую точность.
Многомерные рекуррентные нейронные сети (MDRNN)
RNN/LSTM (долгосрочная память) работают с последовательными данными, но ограничены работой с одномерными данными, такими как текст. Следовательно, они не могут быть прямо распространены на изображения.
Многомерные рекуррентные нейронные сети можно использовать для замены одного рекуррентного соединения в стандартной рекуррентной нейронной сети (RNN) количеством рекуррентных единиц, равным количеству измерений в данных.
Во время прямого прохода в каждой точке последовательности данных скрытый слой сети получает как внешний ввод, так и собственные активации от одного шага назад по всем измерениям.
Основной проблемой в системе распознавания является преобразование двумерных изображений в одномерные последовательности меток. Это делается путем передачи входных данных через иерархию уровней MDRNN с блоками функций активации между ними после каждого уровня RNN.
Высота блоков выбирается таким образом, чтобы постепенно сворачивать 2D-изображения в 1D-последовательности, которые затем можно пометить на выходном слое.
💡
Совет от профессионала: Подробнее о том, как это работает, см. в этом документе об автономном распознавании рукописного ввода с помощью MDRNN. Многомерные рекуррентные нейронные сети нацелены на то, чтобы сделать языковую модель устойчивой к локальным искажениям при каждой комбинации входных измерений (таких как повороты и сдвиги изображения, неоднозначность штрихов и различные стили почерка) и позволить им гибко моделировать многомерный контекст.
Коннекционистская временная классификация (CTC)
Коннекционистская временная классификация (CTC) — это алгоритм, который имеет дело с такими задачами, как распознавание речи, распознавание рукописного ввода и т. д., где все входные данные сопоставляются с выходным классом/текстом.
Распознавание рукописного текста включает сопоставление изображений с соответствующим текстом. Однако мы не знаем, как участок изображения совмещен с символами. Без этой информации традиционные подходы не работают.
Временная классификация коннекционистов (CTC) — это способ обхода без знания того, как определенная часть звуковой речи или изображения почерка соотносятся с определенным символом. Простые эвристики, такие как присвоение каждому символу одной и той же области, не будут работать, поскольку количество места, которое занимает каждый символ, зависит от почерка.
Моделирование последовательности с помощью CTC [источник] Входными данными для этого алгоритма является векторное представление изображения рукописного текста. Нет прямого соответствия между представлением пикселей изображения и последовательностью символов. CTC стремится найти это сопоставление, суммируя вероятности всех возможных совпадений между ними.
Нет прямого соответствия между представлением пикселей изображения и последовательностью символов. CTC стремится найти это сопоставление, суммируя вероятности всех возможных совпадений между ними.
Модели, обученные с помощью CTC, обычно используют рекуррентную нейронную сеть (RNN) для оценки вероятностей для каждого временного шага, поскольку RNN учитывает контекст во входных данных. Он выводит баллы символов для каждого элемента последовательности, представленного матрицей.
Стратегия декодирования наилучшего пути для поиска наиболее вероятного текста [источник]Для декодирования мы можем использовать:
- Декодирование наилучшего пути , которое включает в себя предсказание предложения путем объединения наиболее вероятного символа с отметкой времени для формирования полного слова, который дает лучший путь. На следующей итерации обучения повторяющиеся символы и пробелы удаляются, чтобы лучше декодировать текст.
- Декодер поиска луча, , где предлагается несколько выходных путей с наивысшей вероятностью.
 Пути с меньшей вероятностью отбрасываются, чтобы размер луча оставался постоянным. Результаты, полученные с помощью этого подхода, более точны и часто сочетаются с языковыми моделями для получения значимых результатов.
Пути с меньшей вероятностью отбрасываются, чтобы размер луча оставался постоянным. Результаты, полученные с помощью этого подхода, более точны и часто сочетаются с языковыми моделями для получения значимых результатов.
💡
Совет от профессионала: Ознакомьтесь с автокодировщиками в глубоком обучении: руководство и примеры использованияМодели-трансформеры
RNN идеально подходят для моделирования текстовых данных, поскольку они могут фиксировать их временной аспект. Но они также связаны со стоимостью обучения, поскольку последовательные конвейеры предотвращают распараллеливание и ограничение памяти при обработке более длинных последовательностей. Модели-трансформеры применяют другую стратегию, используя само-внимание для запоминания всей последовательности.
Неповторяющийся подход к почерку достигается с помощью моделей-трансформеров.
Обращайте внимание на то, что вы читаете
Модель трансформатора в сочетании с многоуровневым уровнем самоконтроля как на визуальном, так и на текстовом уровне может изучать связанные с языковой моделью зависимости последовательностей символов, подлежащих декодированию.
Знание языка встроено в саму модель, поэтому нет необходимости в каких-либо дополнительных этапах постобработки с использованием языковой модели. Он также хорошо подходит для прогнозирования выходных данных, которые не являются частью словаря.
Обзор архитектуры модели «Внимание тому, что вы читаете» [источник]Архитектура «Внимание тому, что вы читаете» состоит из двух частей:
- Транскрайбер текста , предназначенный для вывода декодированных символов путем взаимного обслуживания визуальные и языковые функции
- Кодировщик визуальных функций предназначен для извлечения соответствующей информации из изображений рукописного текста путем сосредоточения внимания на различных позициях символов и их контекстуальной информации

Сети кодировщика-декодера и внимания
Архитектура модели кодировщика-декодера в сочетании с сетью внимания [источник]Обучающие системы распознавания рукописного ввода всегда страдают от нехватки обучающих данных, поскольку невозможно создать набор со всеми комбинациями языков, узоры штрихов и т. д.
Чтобы решить эту проблему, этот метод использует предварительно обученные векторы признаков текста в качестве отправной точки. Современные модели намекают на использование механизма внимания в сочетании с RNN, чтобы сосредоточиться на полезных функциях в каждой отметке времени.
Полную архитектуру модели можно разделить на четыре этапа:
1. Преобразование
Сеть CNN обучена локализации. Он берет входное изображение и изучает координаты реперных точек, используемых для захвата формы текста. Поскольку рукописные слова могут быть наклонены, перекошены, искривлены или иметь неправильную форму, изображения входных слов нормализуются путем применения некоторых преобразований.
2. Извлечение признаков
Особенности в рукописном тексте включают углы штриха, серии наклонов и т. д., для которых можно использовать архитектуру типа ResNet для кодирования нормализованного входного изображения в 2D-визуализацию. карта характеристик.
3. Моделирование последовательности
Функции, извлеченные на предыдущем шаге, используются в качестве последовательного фрейма (так же, как текст слева направо). Он декодируется с использованием двунаправленного LSTM для последовательного моделирования, чтобы сохранить контекстную информацию в последовательности с обеих сторон и распознать каждый символ независимо, принимая во внимание абстракции более высокого уровня.
4. Предсказание
Выходные векторы, содержащие контекстную информацию из последнего декодера, преобразуются в слова. Во-первых, выходной вектор необходимо передать в полносвязный линейный слой, чтобы получить вектор размера словаря, который используется для обучения модели. Затем к этому вектору применяется функция softmax в качестве функции активации, чтобы получить оценку вероятности для каждого слова в словаре.
Scan, Attend and Read
Scan, Attend and Read — метод, предложенный для сквозного распознавания рукописного ввода с использованием механизма внимания. Он сканирует всю страницу за один раз. Следовательно, это не зависит от предшествующей сегментации всего слова на символы или строки. Алгоритм
Scan-As-You-Read для распознавания рукописного ввода с многомерным чередованием слоев LSTM [источник] Этот метод использует многомерную архитектуру LSTM (MDLSTM) в качестве средства извлечения признаков, аналогичного описанному выше. Единственным отличием является последний слой, где извлеченные карты объектов свернуты по вертикали, а для распознавания соответствующего текста применяется функция активации softmax.
Используемая здесь модель внимания представляет собой гибридную комбинацию внимания, основанного на содержании, и внимания, основанного на местоположении. Модули декодера LSTM принимают предыдущую карту состояния и внимания, а также функции кодировщика для генерации окончательного выходного символа и вектора состояния для следующего прогноза.
Convolve, Attend и Spell
Распознавание рукописного текста во многом связано с распознаванием образов.
Последовательные нейронные сети, поддерживаемые механизмом внимания, могут стать передовым методом распознавания рукописного ввода, как подчеркивается в этой статье о модели Convolve, Attend и Spell.
Convolve, Attend and Spell — это модель последовательного распознавания рукописных слов, основанная на механизме внимания. Архитектура состоит из трех основных частей:
- кодировщик, состоящий из CNN и двунаправленного GRU
- механизм внимания, фокусирующийся на соответствующих функциях
- декодер, образованный однонаправленным GRU, способный произносить соответствующее слово по буквам
(RNN) лучше всего подходят для временного характера текста. В сочетании с такими рекуррентными архитектурами механизмы внимания играют решающую роль в сосредоточении внимания на нужных функциях на каждом временном шаге.
В сочетании с такими рекуррентными архитектурами механизмы внимания играют решающую роль в сосредоточении внимания на нужных функциях на каждом временном шаге.
Модели последовательностей (seq2seq) следуют парадигме кодер-декодер.
Работа Listen, Attend и Spell для распознавания рукописного ввода [источник]Кодер состоит из сверточной нейронной сети (CNN), которая извлекает визуальные особенности из письменного текста, последовательно закодированного RNN. Декодер — это еще одна RNN, которая декодирует по одному символу за раз, создавая таким образом целое слово и записывая его по буквам .
Механизм внимания связывает кодировщик и декодер, чтобы обеспечить высококоррелированный вектор контекста, который фокусируется на характеристиках каждого символа на каждом временном шаге декодирования.
Эффективность распознавания кодировщика-декодера или любого другого алгоритма распознавания последовательностей seq2seq ухудшается, если вводимый текст длинный из-за таких ограничений, как зависимость от большого диапазона и т.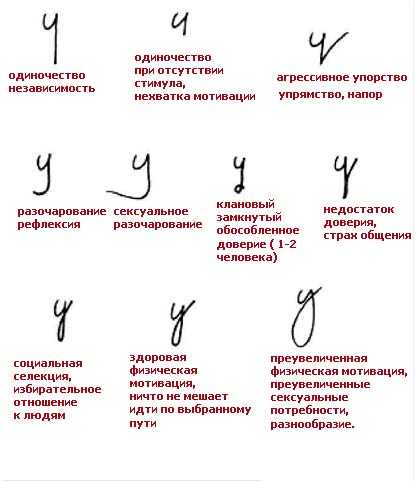 д. Единицы внимания помогают искать набор позиций в скрытых состояниях кодировщика, где находится наиболее важная информация. доступный.
д. Единицы внимания помогают искать набор позиций в скрытых состояниях кодировщика, где находится наиболее важная информация. доступный.
Генерация рукописного текста
Генерация синтетического рукописного текста — это задача создания реалистично выглядящего рукописного текста. Его можно использовать для улучшения существующих наборов данных.
Модели глубокого обучения требуют большого количества данных для обучения, а получение обширного корпуса аннотированных изображений рукописного ввода для разных языков является трудоемкой задачей.
Мы можем использовать генеративно-состязательные сети для создания обучающих данных для решения этой проблемы.
ScrabbleGAN
Распознавание рукописного текста имеет ограниченный объем обучающих данных, поскольку у каждого человека свой уникальный стиль письма. Сбор разнообразного набора наборов данных обходится очень дорого, а аннотировать текст еще сложнее.
Чтобы свести к минимуму эту потребность в сборе данных и аннотировании рукописных данных, хорошо подходит полууправляемое обучение. Он использует комбинацию размеченных и неразмеченных выборок данных для повышения производительности моделей. По сравнению с полностью контролируемыми моделями, он учится определять лучшие функции и лучше адаптироваться к невидимым изображениям.
Он использует комбинацию размеченных и неразмеченных выборок данных для повышения производительности моделей. По сравнению с полностью контролируемыми моделями, он учится определять лучшие функции и лучше адаптироваться к невидимым изображениям.
ScrabbleGAN — это полууправляемый подход к синтезу рукописных текстовых изображений. Он основан на генеративной модели, которая может генерировать изображения слов произвольной длины с использованием полностью сверточной сети.
Кроме того, генератор достаточно умен, чтобы манипулировать результирующим стилем текста и штрихами. В дополнение к дискриминатору D результирующее изображение также оценивается сетью распознавания текста R. В то время как D способствует реалистичному стилю рукописного ввода, R способствует тому, чтобы результат был удобочитаемым и соответствовал введенному тексту.
💡 Совет от профессионала: Чтобы узнать, как использовать синтетические данные для обучения моделей машинного обучения, прочтите статью Что такое синтетические данные в машинном обучении и как их генерироватьКлючевой вывод
Технология распознавания рукописного ввода находится на переднем крае исследований ИИ.
Это полезно во многих отраслях, обеспечивая лучшее хранение данных, более быстрый поиск информации, доступность и более эффективные бизнес-процессы.
Появляются новые методы решения таких проблем, как непредсказуемость, изменчивость или качество изображения.
A few of the most prominent architectures include:
- CapsNets
- Multidimensional Recurrent Neural Networks
- Connectionists Temporal Classification
- Transformer models
- Encoder-decoder and attention networks
- Generative adversarial networks
neural networks — Can глубокое обучение определяет, принадлежат ли два образца почерка одному и тому же человеку?
Похоже, эта бумага делает именно то, что вам нужно: распознает авторство образцов почерка, даже если тексты не совпадают.
«DeepWriter: многопоточная глубокая CNN для Независимая от текста идентификация автора» Линьцзе Син, Юй Цяо. 2016.
Независимая от текста идентификация автора затруднена из-за огромного разнообразия письменного содержания и неоднозначного стиля письма разных авторов.
В этой статье предлагается DeepWriter, глубокая многопоточная CNN для изучения глубокого мощного представления для распознавания писателей. DeepWriter принимает локальные рукописные патчи в качестве входных данных и обучается с потерей классификации softmax. Основные вклады: 1) мы разрабатываем и оптимизируем многопотоковую структуру для задачи идентификации автора; 2) мы вводим обучение дополнению данных для повышения производительности DeepWriter; 3) мы вводим стратегию сканирования патчей для обработки текстового изображения разной длины. Кроме того, мы обнаружили, что разные языки, такие как английский и китайский, могут иметь общие черты для идентификации автора, а совместное обучение может повысить эффективность. Экспериментальные результаты на наборах данных IAM и HWDB показывают, что наши модели обеспечивают высокую точность идентификации: 99,01% для 301 автора и 97,03% для 657 авторов с вводом одного предложения на английском языке, 93,85% для 300 авторов с вводом одного китайского символа, что значительно превосходит предыдущие методы.
Кроме того, наши модели обеспечивают точность 98,01% для 301 автора, использующего только 4 английских алфавита в качестве входных данных.
Сиамские сети используются для сравнения таких вещей, как подписи; кажется разумным попытаться распространить этот метод на анализ почерка. Одна из проблем заключается в том, что, хотя подписи подобны «штампам» в том смысле, что писатель захочет воспроизвести один и тот же символ снова и снова, два образца почерка могут не содержать одних и тех же слов и фраз. Таким образом, успех или провал проекта зависит от того, сможет ли нейронная сеть распознать стиль письма, отличный от слов.
Джейн Бромли, Изабель Гийон, Янн ЛеКун, Эдуард Зикингер и Рупак Шах. «Проверка подписи с использованием« сиамской »нейронной сети с временной задержкой». Лаборатории Белла AT&T. 1994
В этой статье описывается алгоритм проверки подписи, написанной на планшете с перьевым вводом. Алгоритм основан на новой искусственной нейронной сети, называемой «сиамской» нейронной сетью.
Эта сеть состоит из двух одинаковых подсетей, соединенных на своих выходах. Во время обучения две подсети извлекают признаки из двух сигнатур, а соединяющий нейрон измеряет расстояние между двумя векторами признаков. Проверка состоит из сравнения извлеченного вектора признаков с сохраненным вектором признаков для подписавшего. Подписи, которые ближе к этому сохраненному представлению, чем выбранный порог, принимаются, все остальные подписи отклоняются как поддельные.
Другой подход заключается в использовании стратегий потери триплетов и внедрения, таких как используемые в FaceNet. Затем вы каким-то образом сравниваете вложения, чтобы решить, имеют ли два изображения одного и того же или другого автора. Успех на лицах, снятых под разными углами и в разных условиях освещения, многообещающий и, возможно, лучше подходит для сопоставления образцов почерка.
Флориан Шрофф, Дмитрий Калениченко, Джеймс Филбин. «FaceNet: унифицированное встраивание для распознавания лиц и кластеризации»
Несмотря на недавние значительные достижения в области распознавания лиц, эффективная проверка и распознавание лиц в больших масштабах создает серьезные проблемы для существующих подходов.
