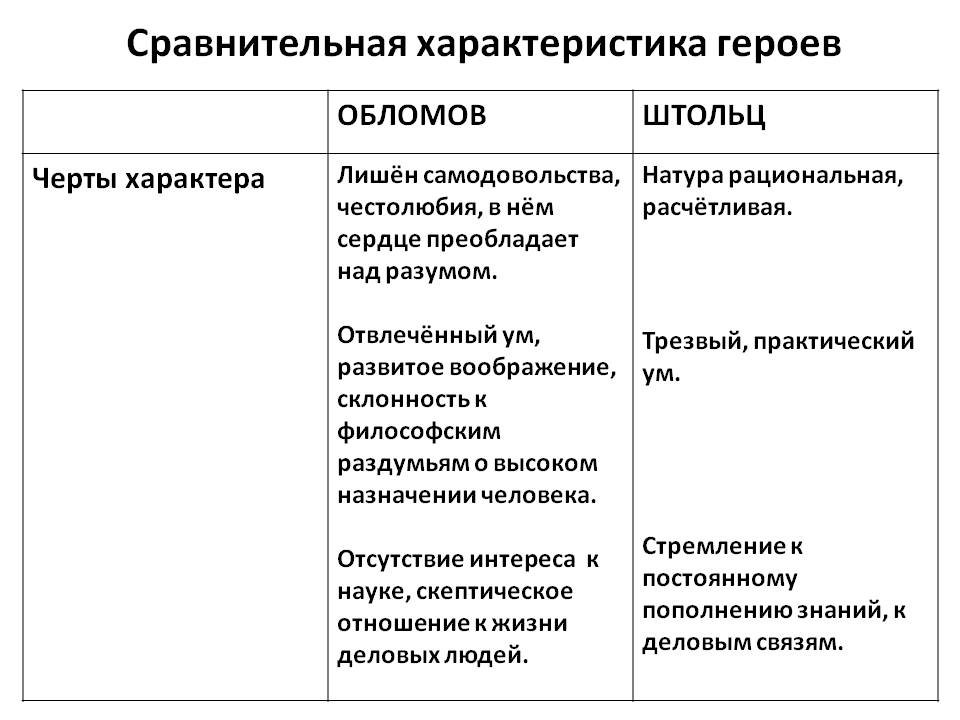
Характеры какие: Черты Характера Человека | Список И Их Значение?
Какие действия родителей перед сном формируют хороший характер у детей
25 ноября 2022 17:56 Ольга Мурая
То, что малыш делает перед сном, влияет на качество и продолжительность сна, а также на его будущий характер.
Фото Unsplash.
Вырастить ребёнка счастливым и уверенным в себе человеком – мечта большинства родителей. Учёные выяснили, что очень серьёзную лепту в этот процесс вносят… вечерние ритуалы отхода ко сну. Какие же использовать?
Хороший качественный сон играет огромную роль в развитии ребёнка.
Плохое качество сна вредит работе мозга, связанной с регулированием поведения. Это может приводить к трудностям с самоконтролем и восприятием отрицательных эмоций ребёнком.
Исследователи предлагают родителям обратить внимание на то, как они воспитывают своих детей и какие привычки, связанные со сном, им прививают.
Но, для того чтобы дать родителям более точные рекомендации, учёным нужно было сначала самим понять, какие методы «успокоения» детей перед сном используются в разных культурах и к каким результатам приводят.
Группа международных исследователей стремилась выяснить, как межкультурные различия в «стратегиях засыпания» влияют на развитие темперамента малышей.
Исследователи определяют темперамент тремя всеобъемлющими факторами:
Динамизм (ДИН), который отражает положительные эмоции, склонность к сближению с другими, активность и энтузиазм.
Отрицательная эмоциональность (ОЭ), которая отражает общую склонность к стрессу, в том числе в ситуациях, вызывающих страх, гнев, печаль и дискомфорт.
Произвольный контроль (ПК), включающий навыки регулирования внимания и получение удовольствия от спокойной деятельности.
Авторы нового исследования изучали влияние различных родительских методов «укладывания ребёнка» на его темперамент в 14 культурах (Бельгия, Бразилия, Чили, Китай, Финляндия, Италия, Мексика, Нидерланды, Румыния, Россия, Испания, Южная Корея, Турция и США).
Они предположили, что пассивные способы помочь ребёнку заснуть (например, объятия, пение или чтение), но не активные методы (например, прогулки, поездки на машине и игры), будут положительно влиять на темперамент ребенка.
Так учёные выяснили, что разные подходы действительно связаны с развитием темперамента малышей.
Так, в странах, в которых больше полагались на пассивные стратегии (США, Финляндия и Нидерланды), дети ясельного возраста демонстрировали более высокие показатели общительности (более высокий показатель ДИН).
С другой стороны, суетливый или «трудный» темперамент (высокий показатель ОЭ) в значительной степени был связан с активными методами отхода ко сну.
В целом, пассивные методы «укладывания» оказались связаны с более низкими показателями ОЭ и более высокими показателями ДИН на уровне культуры и более высоким произвольным контролем на индивидуальном уровне.
Активные методы поддержки сна, принятые в таких странах, как Румыния, Испания и Чили были связаны с более высоким ОЭ только на индивидуальном уровне.
Упрощая, можно заключить, что успокоение ребёнка перед сном с помощью объятий, чтения книг или пения колыбельных способствует развитию у него склонности к общению, усидчивости и умению регулировать стресс.
А вот попытки «измотать» малыша перед сном с помощью физической активности и эмоционального возбуждения способствуют развитию раздражительности и нервозности у ребёнка.
Исследование было опубликовано в издании Frontiers in Psychology.
Ранее мы рассказывали о том, как один музыкальный аккорд помогает избавиться от ночных кошмаров, а ещё о том, кому противопоказан дневной сон.
Больше новостей из мира науки вы найдёте в разделе «Наука» на медиаплатформе «Смотрим».
культура наука ребенок характер сон воспитание дети ритуал общество темперамент новости
О настройках медиафайлов в Twitter
Во всех учетных записях Twitter имеются настройки медиафайлов, которые позволяют Twitter понять, какого рода материалы вы размещаете, а также помогают другим пользователям найти тип содержимого, который им интересен.
За счет правильных настроек медиафайлов Twitter может идентифицировать материалы, потенциально носящие деликатный характер, которые другие пользователи, возможно, не хотели бы видеть, например материалы с изображением сцен насилия или обнаженной натуры. Если вы намерены регулярно публиковать такие материалы, просим вас изменить свои настройки медиафайлов следующим образом.
Изменение настроек медиафайлов
Шаг 1
Нажмите значок профиля на панели навигации слева вверху.
Шаг 2
Нажмите Настройки и конфиденциальность.
Шаг 3
Нажмите Конфиденциальность и безопасность.
Шаг 4
Нажмите Ваши твиты.
Шаг 5Установите переключатель Отметить медиафайлы в вашем твите как материал, который может носить деликатный характер.
Примечание. Если эта настройка включена, другие пользователи при просмотре вашего профиля могут получать предупреждения о том, что в вашей учетной записи, возможно, имеются медиафайлы, носящие потенциально деликатный характер, и должны будут подтвердить, что они действительно хотят просмотреть их. Пользователи, которые выбрали настройку «Показывать медиафайлы, которые могут носить деликатный характер», могут просматривать вашу страницу без предупреждающего сообщения.
Шаг 1
Нажмите значок _ на панели навигации слева вверху.
Шаг 2
Выберите Настройки и конфиденциальность.
Шаг 3
В раскрывающемся меню выберите Конфиденциальность и безопасность.
Шаг 4
Нажмите Ваши твиты.
Шаг 5
Установите переключатель Отметить медиафайлы в вашем твите как материал, который может носить деликатный характер, так чтобы он изменил цвет на синий.
Примечание. Если эта настройка включена, другие пользователи при просмотре вашего профиля могут получать предупреждения о том, что в вашей учетной записи, возможно, имеются медиафайлы, носящие потенциально деликатный характер, и должны будут подтвердить, что они действительно хотят просмотреть их. Пользователи, которые выбрали настройку «Показывать медиафайлы, которые могут носить деликатный характер», могут просматривать вашу страницу без предупреждающего сообщения.
Шаг 1
Войдите в свою учетную запись на веб-сайте twitter.com.
Шаг 2
Нажмите значок Еще.
Шаг 3
В раскрывающемся меню выберите пункт Настройки и конфиденциальность.
Шаг 4
Перейдите в раздел настроек Конфиденциальность и безопасность.
Шаг 5
В разделе Ваши твиты установите флажок Отметить медиафайлы в вашем твите как материал, который может носить деликатный характер.
Примечание. Если эта настройка включена, другие пользователи при просмотре вашего профиля могут получать предупреждения о том, что в вашей учетной записи, возможно, имеются медиафайлы, носящие потенциально деликатный характер, и должны будут подтвердить, что они действительно хотят просмотреть их. Пользователи, которые выбрали настройку «Показывать медиафайлы, которые могут носить деликатный характер», могут просматривать вашу страницу без предупреждающего сообщения.
Возможность добавлять однократные предупреждения о деликатном характере содержимого к фотографиям и видео, которые содержатся в твите, теперь доступна для всех на Android, iOS и в Интернете.
Чтобы добавить предупреждение о медиаконтенте, коснитесь или нажмите на значок флажка при редактировании фотографии или видео после того, как вы прикрепили их к твиту.
Управлять отображением материалов, носящих деликатный характер, можно в настройках медиафайлов.
Что произойдет, если я буду публиковать медиафайлы, носящие деликатный характер, не изменив своих настроек?
Если кто-то пожалуется, что в одном из ваших твитов содержится медиафайл, носящий деликатный характер, этот медиафайл поступит на рассмотрение сотрудников Twitter. Если мы обнаружим, что этот медиафайл не был отмечен как носящий деликатный характер во время загрузки, произойдет следующее.
- Мы можем отметить ваш медиафайл как носящий деликатный характер, а если контент деликатного характера содержится в прямой видеотрансляции — удалить ее.
- Мы также можем изменить настройки вашей учетной записи, активировав параметр Отметить медиафайлы в вашем твите как материал, который может носить деликатный характер, чтобы все будущие публикации имели соответствующие отметки.
Вы сможете изменить свои настройки медиафайлов на странице настроек учетной записи, но это изображение и все остальные отмеченные изображения останутся отмеченными как носящие деликатный характер.
Если вы регулярно загружаете изображения, не отмечая их надлежащим образом, мы можем:
- отметить ваши медиафайлы как носящие деликатный характер;
- изменить настройки вашей учетной записи, активировав параметр Отметить медиафайлы в вашем твите как материал, который может носить деликатный характер без возможности изменения, чтобы ваши последующие публикации содержали предупреждающие сообщения, с которыми пользователям будет необходимо ознакомиться перед просмотром медиафайлов.
Также Twitter может использовать автоматизированные методы выявления и маркировки медиафайлов деликатного характера и учетных записей, которые часто публикуют в твитах медиафайлы деликатного характера.
Что произойдет, если мое изображение профиля нарушает правила Twitter?
Если изображение вашего профиля или шапки нарушает правила Twitter, мы можем временно приостановить действие вашей учетной записи и удалить эти материалы. Повторные нарушения приведут к тому, что действие вашей учетной записи будет приостановлено без возможности возобновления.
Кроме того, ваша учетная запись может быть заблокирована, если в вашем профиле содержатся медиaфайлы, нарушающие правила Twitter. Чтобы разблокировать учетную запись, необходимо выполнить инструкции и удалить медиафайл, нарушающий правила Twitter. Если ваша учетная запись была заблокирована, дополнительные сведения можно найти в этой статье.
Можно ли оспорить решение Twitter?
Если действие вашей учетной записи приостановлено в связи с тем, что ваше изображение профиля или шапки содержит сцены насилия или материалы для взрослых, вы можете оспорить это решение, выполнив вход и подав апелляционную жалобу на этой странице.
Оспорить решение Twitter о бессрочном включении в настройках учетной записи параметра Отметить медиафайлы в моем твите как материал, который может носить деликатный характер в связи с неоднократными нарушениями правил маркировки материалов, носящих деликатный характер, в настоящее время невозможно.
Разработка статистической викторины «Какой персонаж»
Эта страница служит руководством для статистической викторины «Какой персонаж» , а также для версии отчета коллег и пары.
Эта страница находится в разработке! Пожалуйста, зайдите как-нибудь для полированной версии!
Предыстория
Когда я, ваш автор, рассказывал людям, что я публикую личностные тесты в Интернете, меня часто спрашивали, означает ли это, что я работал на веб-сайт BuzzFeed, пишу их «Какой вы _________ персонаж?» викторины личности. И я должен был бы ответить, что нет, я больше интересуюсь наукой и человеческой природой, чем развлечением; эти викторины забавны, но не настолько значимы. И это не критика BuzzFeed! Ценность BuzzFeed (и всех других источников тестирования персонажей) подтверждается их популярностью. Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
И это не критика BuzzFeed! Ценность BuzzFeed (и всех других источников тестирования персонажей) подтверждается их популярностью. Это веселые игры. Людям нравится их принимать: дело закрыто. Однако, если вас интересует вопрос о том, как проводить хорошие психологические измерения, я полагаю, что они никогда не предлагали много интересного для размышлений. Я создал этот тест в 2019 году после того, как у меня появилась идея представить каждый символ в виде вектора, который можно заполнить краудсорсинговыми данными. И это на самом деле дало мне много интересных вещей для размышлений! Поэтому я немного отказываюсь от своего прежнего предубеждения против идеи характерной личности.
Дополнительной целью этого проекта было создание набора данных, который можно было бы использовать в статистических исследованиях и образовании. Я думаю, что этот набор данных отлично подходит для обучения факторному анализу или алгоритмам кластеризации. Из-за этой дополнительной цели набор данных был разработан так, чтобы он был намного богаче, чем это было бы необходимо только для создания теста.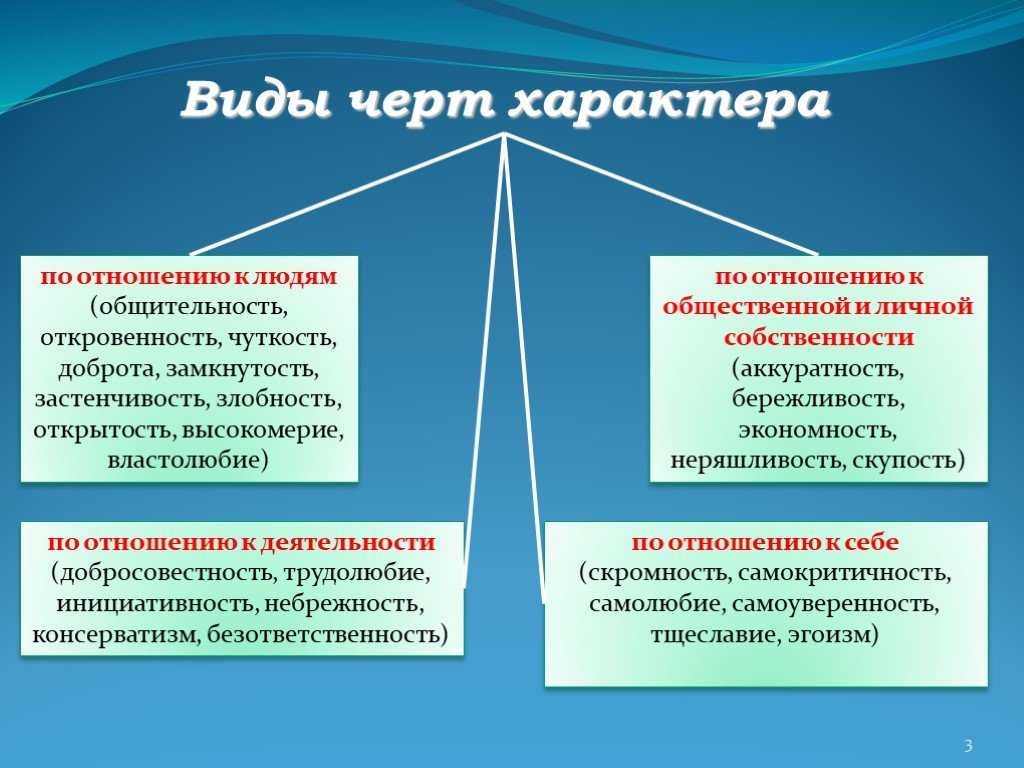 Например, количество функций, по которым пользователи оценивают персонажей, намного больше и разнообразнее.
Например, количество функций, по которым пользователи оценивают персонажей, намного больше и разнообразнее.
Сбор рейтингов персонажей
Вместо того, чтобы создатель теста решал, каким должен быть профиль каждого персонажа, основываясь только на их мнении, мнения большого количества людей будут усредняться для создания профилей персонажей.
Был выбран формат 100-балльной шкалы, которая закреплена на каждом конце прилагательным.
Для начала тестовый набор данных был заполнен добровольцами из Reddit (начиная с персонажей «Игры престолов» и «Гарри Поттера»), но как только работоспособная версия теста была запущена, база данных стала самоподдерживающейся благодаря добровольцам, набранным из людей, принимавших участие в тестировании. тестовое задание. После того, как пользователь ответил на опрос личностного рейтинга, но до того, как он просмотрел свои результаты, его спрашивают, не хотят ли они оценить некоторых персонажей. Уровень отказа составляет около 35%. Затем добровольцев просят выбрать любые вымышленные вселенные, о которых они знают, из списка, а затем персонажи из этой вселенной сопоставляются с элементами из набора функций (обычно случайным образом), и они оценивают их. После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
Затем добровольцев просят выбрать любые вымышленные вселенные, о которых они знают, из списка, а затем персонажи из этой вселенной сопоставляются с элементами из набора функций (обычно случайным образом), и они оценивают их. После этого задается еще несколько вопросов об отношении пользователя к этой вымышленной вселенной и некоторые демографические вопросы. Их опрос, где оценивались персонажи, менялся со временем, но в основном выглядел так, как показано на скриншоте ниже.
Шкала идет от 1 (крайний левый) до 100 (крайний правый). Пользователь не получил инструкций по этому поводу в рейтинговом опросе, но во время основной части теста они использовали аналогичные шкалы ползунков для оценки себя, которые отображали числовые значения, и поэтому пользователь должен был установить связь и понять, что шкала была. Количество оценок, которые дал бы конкретный пользователь, менялось с течением времени. Первоначально пользователям было назначено 30 оценок, но это оказалось слишком много, поэтому в настоящее время пользователям назначено 15 оценок, если только для вселенной, где данные редки, им назначено 25.
После этого было задано несколько вопросов, которые должны помочь оценить отношение этого пользователя к работе, как показано ниже.
Затем, наконец, были заданы некоторые демографические вопросы, чтобы представить выборку в контексте, изображенном ниже.
Это была последняя страница опроса волонтеров, и после ее отправки пользователи сразу же получали результаты. Эта страница также собирала согласие на использование данных пользователя в качестве последнего вопроса. Данные пользователей, которые не ответят утвердительно на этот вопрос, удаляются.
С помощью этой процедуры было собрано очень большое количество рейтингов. На приведенном ниже графике показано количество завершенных опросов в день с момента преобразования этого опроса в текущий рабочий процесс.
С учетом того, что каждый пользователь поставил до 30 оценок в одном опросе, в общей сложности было сделано более 69 496 000 оценок, распределенных по 400 элементам для 1750 символов. Они были распределены несколько неравномерно, так как более известные вселенные получают больше оценок, но были приняты меры, чтобы каждый элемент для каждого персонажа в базе данных получил не менее 3.
Генерация биполярных шкал
Формат элемента для викторины и набора данных был выбран в виде шкалы от 1 до 100 с закрепленным текстом на обоих концах. Это не самый распространенный формат в психологических измерениях, на самом деле рейтинговые шкалы с ползунками имеют существенные проблемы, за которые я ранее их критиковал. Причина, по которой был выбран этот формат, связана с соображениями пользовательского опыта. Чтобы сделать работу викторины понятной для пользователей, на странице результатов должен быть график, а график лучше выглядит с высокой степенью детализации. Например, если бы ответы пользователей оценивались по шкале от 1 до 5, составленная из них точечная диаграмма выглядела бы очень неуклюжей.
Элементы были созданы вашим автором с течением времени, пока их не стало 400. Это гораздо больше элементов, чем реально может быть использовано в викторине. Тест из 400 вопросов был бы слишком длинным. Но наличие всех этих элементов позволяет нам оценивать и выбирать наиболее эффективные элементы. Это также делает набор данных более полезным для образовательных целей.
Это также делает набор данных более полезным для образовательных целей.
Один из способов оценить, насколько хорош предмет, насколько он хорош. И этот метод более или менее похож на то, как делаются другие тесты персонажей: создатель задает вопросы, которые им кажутся хорошими. Как объяснялось ранее, суждение многих лучше, чем суждение одного. Итак, эта проблема была краудсорсингом для тестирования пользователей в опросе, который выглядел следующим образом.
Этот опрос проводился до тех пор, пока не менее 500 человек не высказали свое мнение по каждому вопросу. Ниже приведены вопросы с наивысшим и наименьшим средним баллом (4 = определенно включены; 1 = определенно исключены).
Проверка достоверности оценок пользователей
Предпосылка этой викторины заключается в том, что объединение оценок различных пользователей повышает их точность, но это предположение, которое не может быть верным. Например, если личность персонажа полностью находится в глазах смотрящего и не имеет согласованности между разными оценщиками, то идея любого теста на определение личности персонажа бессмысленна. Этот вопрос известен как межэтническая надежность. Говорить о характере определенного типа будет иметь смысл только в том случае, если люди согласны с тем, что персонаж именно такой. Обычно это измеряется коэффициентом внутриклассовой корреляции (ICC1). Значение ICC варьируется от 0 до 1. Где 0 означает отсутствие согласия, а 1 — полное согласие. В таблице ниже представлены 10 вопросов с самой высокой и самой низкой межоценочной надежностью.
Этот вопрос известен как межэтническая надежность. Говорить о характере определенного типа будет иметь смысл только в том случае, если люди согласны с тем, что персонаж именно такой. Обычно это измеряется коэффициентом внутриклассовой корреляции (ICC1). Значение ICC варьируется от 0 до 1. Где 0 означает отсутствие согласия, а 1 — полное согласие. В таблице ниже представлены 10 вопросов с самой высокой и самой низкой межоценочной надежностью.
Некоторые вопросы были более надежными, чем другие. Некоторые вопросы имели очень низкую надежность, и, глядя на них, это имеет смысл. Все элементы с низкой надежностью кажутся немного запутанными. Вопрос, который показал самую низкую надежность, — это контраст между «правополушарным» и «левополушарным». Этот вопрос является отсылкой к поп-психологической идее личности о том, что люди предпочитают использовать одну сторону своего мозга и что каждая сторона имеет определенные функции. Низкая согласованность оценок по этому вопросу совпадает с моим предыдущим опытом работы с этой идеей. В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
В свое время я попытался создать свою собственную меру левополушарного мозга по сравнению с правым полушарием и обнаружил, что это была в основном бессвязная/бессмысленная идея. Каждое определение того, что, по их мнению, значит быть левым или правым полушарием, слишком сильно различалось, чтобы вообще быть полезным. См. раздел «Разработка шкалы доминирования открытого полушария мозга».
Мы можем построить график зависимости надежности каждого вопроса от средней оценки вопроса, полученного в опросе, где пользователей спрашивали, какие вопросы, по их мнению, следует использовать в викторине. Некоторые точки были помечены, чтобы помочь с интерпретацией.
Корреляция между ними была положительной, но умеренной (r=0,37). Глядя на отдельные точки, мы можем понять, почему это имеет смысл. Пользователи, как правило, могли сказать, какие вопросы бессмысленны, и соглашались, что их не следует использовать в тесте. Некоторые вопросы были исключениями, когда они были надежными, но по-прежнему получали низкое одобрение пользователей. Одним из них был пункт молодой (не старый) . Это второй самый надежный вопрос, но он получил очень низкие оценки пользователей. И в этом есть смысл, пользователи не любят этот вопрос, потому что он бессмысленный, они не любят его, потому что он не о личности. Итак, вы можете видеть, как это демонстрирует, что важно, чтобы вопрос был надежным, но надежности недостаточно.
Одним из них был пункт молодой (не старый) . Это второй самый надежный вопрос, но он получил очень низкие оценки пользователей. И в этом есть смысл, пользователи не любят этот вопрос, потому что он бессмысленный, они не любят его, потому что он не о личности. Итак, вы можете видеть, как это демонстрирует, что важно, чтобы вопрос был надежным, но надежности недостаточно.
Причины ненадежности
Моделирование рейтингов личности персонажа
Итак, у нас есть все эти рейтинги персонажей, и мы можем спросить: «Какая модель личности персонажа является лучшей?» Набор данных содержит 400 значений для каждого символа, но, возможно, некоторые из этих значений избыточны? Вероятно, вы могли бы хорошо описать символы с гораздо менее чем 400 значениями на символ. Типичный анализ для этого в психометрии называется факторным анализом. Факторный анализ пытается объяснить больший набор наблюдаемых значений меньшим набором фундаментальных причин.
Когда вы запускаете факторный анализ, первое, на что вы смотрите, это «график осыпи». Факторный анализ извлекает факторы по одному, каждый раз пытаясь заставить извлеченный фактор выполнять как можно больше работы, поэтому каждый последующий фактор выполняет меньше работы, чем предыдущий. Вы можете посмотреть, какую дисперсию объясняет каждый фактор, а затем сделать вывод о том, насколько они важны. График осыпи, полученный в результате факторного анализа 400 значений для 1600 символов, приведен ниже.
Факторный анализ извлекает факторы по одному, каждый раз пытаясь заставить извлеченный фактор выполнять как можно больше работы, поэтому каждый последующий фактор выполняет меньше работы, чем предыдущий. Вы можете посмотреть, какую дисперсию объясняет каждый фактор, а затем сделать вывод о том, насколько они важны. График осыпи, полученный в результате факторного анализа 400 значений для 1600 символов, приведен ниже.
Интерпретация сюжета осыпи — это больше искусство, чем наука, но я хочу сказать, что вижу 8 факторов, которые, похоже, работают здесь. Поэтому для остальной части анализа в этом разделе я буду рассматривать только первые 8 извлеченных факторов. Факторный анализ вычисляет нагрузку каждой переменной на каждый фактор. Нагрузка — это то, как анализ оценивает корреляцию этой переменной с фактором. Таким образом, мы можем посмотреть на переменные с наибольшей нагрузкой, чтобы попытаться интерпретировать, что представляет собой каждый фактор. В приведенной ниже таблице показаны нагрузки нескольких основных элементов, которые нагружают каждый фактор.
| Feature | Factor loading | |||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |||||||||
| cruel (not kind) | 0.97 | -0,01 | 0,07 | 0,06 | 0,01 | -0,01 | 0,03 | -0,01 | ||||||||
| Яизование (не нрат0071 | 0.05 | 0.02 | -0.01 | 0.07 | 0.02 | |||||||||||
| angelic (not demonic) | -0.95 | -0.17 | -0.09 | 0.02 | 0 | 0.01 | -0.05 | -0.02 | ||||||||
| scheduled (not spontaneous) | 0.04 | -0.92 | 0.04 | 0.17 | -0.17 | 0.04 | 0 | 0.02 | ||||||||
| serious (not bold) | 0.01 | -0.9 | -0.07 | -0.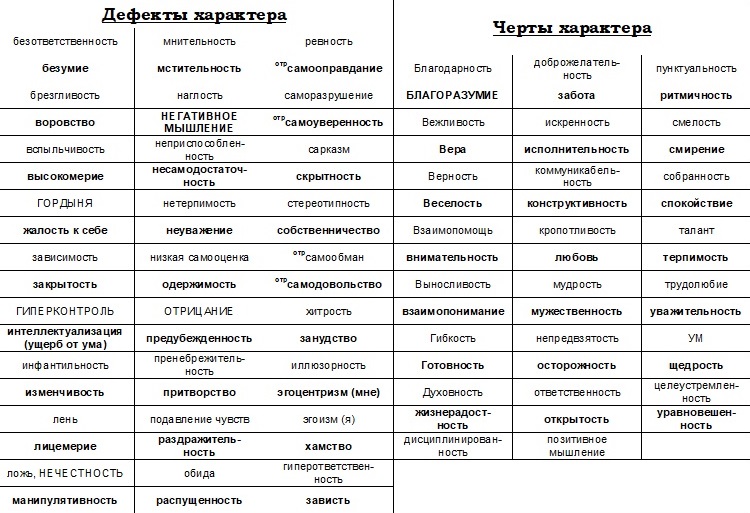 02 02 | -0.09 | -0.06 | 0.24 | 0 | ||||||||
| orderly (not chaotic) | -0.28 | -0.87 | 0.18 | 0.21 | -0.06 | -0.05 | -0.05 | 0.01 | ||||||||
| noob (not pro) | 0.05 | 0.08 | -0.9 | -0.04 | 0.06 | 0 | -0.02 | -0.08 | ||||||||
| mighty (not puny) | -0.06 | -0.02 | 0.9 | 0.01 | 0.19 | 0.03 | 0.07 | -0.08 | ||||||||
| badass (not weakass) | -0.15 | 0.15 | 0.89 | -0.07 | 0.09 | 0.03 | 0.04 | -0.01 | ||||||||
| scruffy (not manicured) | 0.02 | 0.31 | -0.04 | -0.86 | 0.04 | -0.07 | 0.12 | -0.01 | ||||||||
| blue-collar (not ivory-tower) | -0. 31 31 | 0.05 | 0.01 | -0.83 | 0.16 | 0 | -0.02 | -0.03 | ||||||||
| proletariat (not bourgeoisie) | -0.4 | 0.09 | 0.05 | -0.82 | 0.02 | 0 | 0.05 | 0.02 | ||||||||
| sporty (not bookish) | 0.13 | 0.36 | 0.18 | -0.21 | 0.84 | -0.02 | -0.04 | -0.03 | ||||||||
| nerd (not jock ) | -0.27 | -0.22 | -0.3 | 0.06 | -0.8 | 0.07 | -0.02 | 0.15 | ||||||||
| intellectual (not physical) | -0.14 | -0.39 | 0.1 | 0.27 | -0.79 | 0 | 0.03 | 0.14 | ||||||||
| leisurely (not hurried) | -0.07 | 0.45 | 0 | 0.01 | -0.01 | -0. 77 77 | -0,18 | -0,1 | ||||||||
| сонный (не бешеный) | -0,29 | -0,24 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16 | -0,25 | -0,16711170 -0,25 | -0,0071
| aloof (not obsessed) | -0.38 | 0.1 | -0.04 | -0.11 | 0.16 | -0.67 | -0.08 | -0.08 | ||||||||
| sad (not happy) | 0.53 | -0.23 | 0 | -0.1 | -0.04 | 0.05 | 0.76 | -0.01 | ||||||||
| cheery (not sorrowful) | -0.48 | 0.36 | -0.12 | 0.15 | 0.02 | -0.01 | -0.73 | 0.01 | ||||||||
| traumatized (not flourishing) | 0.38 | -0.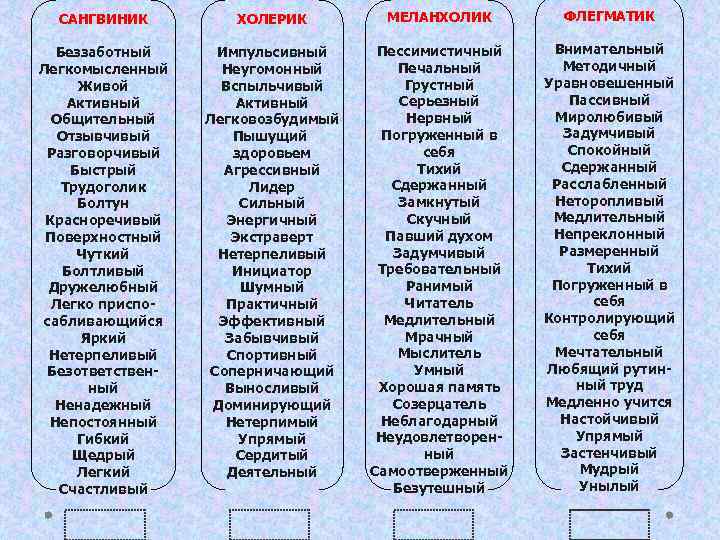 02 02 | -0.26 | -0.26 | 0 | 0.16 | 0.68 | 0.02 | ||||||||
| luddite (not technophile) | 0.09 | 0.04 | -0.07 | -0.19 | 0.18 | -0.06 | 0 | -0.91 | ||||||||
| high-tech (not or low-tech ) | -0,02 | -0,07 | 0,23 | 0,29 | -0,19 | 0,1 | 0,01 | 0,86 | 0,01 | 0,86 | 0,01 | 0,86 | 0,01 | . , могущественный, неряшливый, занудный, энергичный, грустный и высокотехнологичный персонаж, и эти описания независимы. И это может быть своего рода и имеет смысл и кажется разумным. Однако я неравнодушен к фразе «факторный анализ неинтерпретируемый» (украдено у Таля Яркони). Я думаю, что результаты статистического анализа можно интерпретировать только в контексте теории, и у меня нет теории характерной личности — и я не думаю, что она когда-либо могла бы быть.|||
 И помните, что истинное значение отношения между этими двумя вещами выше расчетного значения из-за ненадежности. Это значение будет увеличиваться по мере сбора большего количества данных.
И помните, что истинное значение отношения между этими двумя вещами выше расчетного значения из-за ненадежности. Это значение будет увеличиваться по мере сбора большего количества данных.

 Посмотрите на тот же график, который мы видели раньше, с разбивкой по полу:
Посмотрите на тот же график, который мы видели раньше, с разбивкой по полу: Итак, давайте попробуем отойти от статистики и перейти к науке о данных, чистой обработке чисел. Вместо психологической оценки давайте попробуем осмыслить то, что мы делаем, как механизм рекомендаций с целью максимальной идентификации пользователя. Основным инструментом, используемым здесь, является вопрос, показанный ниже:
Итак, давайте попробуем отойти от статистики и перейти к науке о данных, чистой обработке чисел. Вместо психологической оценки давайте попробуем осмыслить то, что мы делаем, как механизм рекомендаций с целью максимальной идентификации пользователя. Основным инструментом, используемым здесь, является вопрос, показанный ниже:
 Но есть один альтернативный метод сопоставления людей с персонажами, с которыми мы можем провести детальное сравнение: типы личности Майерс-Бриггс. Майерс-Бриггс, или Юнгианский тип, представляет собой систему из 16 типов личности. Это самая популярная система в Интернете, и одним из ее распространенных применений является ввод вымышленных персонажей. Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News):
Но есть один альтернативный метод сопоставления людей с персонажами, с которыми мы можем провести детальное сравнение: типы личности Майерс-Бриггс. Майерс-Бриггс, или Юнгианский тип, представляет собой систему из 16 типов личности. Это самая популярная система в Интернете, и одним из ее распространенных применений является ввод вымышленных персонажей. Обычный формат заключается в том, что кто-то составляет таблицу персонажей из вымышленной вселенной и выбирает по одному примеру, который, по его мнению, подходит для каждого из 16 типов. Обычно это выглядит как мем ниже, который показывает набор символов «Звездных войн» (от Entertainment Earth News): Пользователи оценивают персонажей по типам личности Майерс-Бриггс и Эннеаграммы, и все это объединяется в вердикт сообщества. PDB является самым популярным веб-сайтом для набора текста сообществом Майерс-Бриггс, и его вердикты будут использоваться в этом анализе в качестве ключа для того, к какому типу относится каждый символ в системе Майерс-Бриггс. Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB.
Пользователи оценивают персонажей по типам личности Майерс-Бриггс и Эннеаграммы, и все это объединяется в вердикт сообщества. PDB является самым популярным веб-сайтом для набора текста сообществом Майерс-Бриггс, и его вердикты будут использоваться в этом анализе в качестве ключа для того, к какому типу относится каждый символ в системе Майерс-Бриггс. Из 1600 профилей символов в наборе данных SWCPQ1.0 1537 имеют совпадающие профили в PDB. Для каждого из них у нас есть много тысяч человек, которые и сами сообщили о типе Майерс-Бриггс, и оценили, насколько они похожи на персонажа. На приведенных ниже графиках показано, какой процент каждого типа Майерс-Бриггс дал каждому различную оценку сходства с ними.
Для каждого из них у нас есть много тысяч человек, которые и сами сообщили о типе Майерс-Бриггс, и оценили, насколько они похожи на персонажа. На приведенных ниже графиках показано, какой процент каждого типа Майерс-Бриггс дал каждому различную оценку сходства с ними. Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
Они спрашивают, насколько полезны эти прилагательные, какую работу они выполняют?
 Это означает, что они не очень хорошо передают информацию о добре и зле. А добро и зло — это самое главное, на чем люди основывают свои суждения о том, насколько персонаж похож на них. Учитывая, что сопоставление характеров не было целью, для которой разрабатывались типы личности Майерс-Бриггс, тот факт, что они плохо справляются с этой задачей, на самом деле не опровергает идею 16 типов напрямую. Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс.
Это означает, что они не очень хорошо передают информацию о добре и зле. А добро и зло — это самое главное, на чем люди основывают свои суждения о том, насколько персонаж похож на них. Учитывая, что сопоставление характеров не было целью, для которой разрабатывались типы личности Майерс-Бриггс, тот факт, что они плохо справляются с этой задачей, на самом деле не опровергает идею 16 типов напрямую. Но многие люди в Интернете предположили, что поиск персонажей того же типа, что и у вас, имеет большое значение. Я бы указал на это как на еще один пример распространенного явления, когда люди сильно переоценивают полезность категоризации по типам Майерс-Бриггс. Какая бы викторина ни поставила персонажа, которого они претендовали на более высокое место на странице результатов (после исправления общего количества вариантов), считалась победителем этого совпадения. В общей сложности участвовало 15 реддиторов, и результаты были представлены как «11 побед для OpenPsychometrics и 4 победы для CharacTour» (см. ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления.
Какая бы викторина ни поставила персонажа, которого они претендовали на более высокое место на странице результатов (после исправления общего количества вариантов), считалась победителем этого совпадения. В общей сложности участвовало 15 реддиторов, и результаты были представлены как «11 побед для OpenPsychometrics и 4 победы для CharacTour» (см. ветку на r/SampleSize). Это говорит о том, что викторина на этом веб-сайте имеет лучшую процедуру сопоставления, хотя n = 15 слишком мало для меня, чтобы делать какие-либо супер конкретные заявления. Но в глубине души она не может не задаться вопросом, почему она родилась со способностями.
Но в глубине души она не может не задаться вопросом, почему она родилась со способностями. Он невинен, общителен и любит все лето. Олаф может быть немного наивен, но его искренность и добродушный темперамент делают его настоящим другом Анны и Эльзы.
Он невинен, общителен и любит все лето. Олаф может быть немного наивен, но его искренность и добродушный темперамент делают его настоящим другом Анны и Эльзы.